
Flux.1 has arrived, setting a new benchmark in the world of open-weight image models. With 12 billion parameters, it surpasses industry giants like Midjourney V6, OpenAI’s Dall-E 3, and Stability AI’s SD3 Ultra in terms of image quality and performance.
The team behind Flux.1 has an interesting history.
They’re the original developers of the technology that powers Stable Diffusion and the inventors of latent diffusion. Following some internal issues at Stability AI, key team members left to form a new startup called Black Forest Labs.
This kind of “tech exodus” often leads to innovation. When talented individuals branch out on their own, they’re free to pursue bold new ideas without the constraints of larger organizations.
Flux.1 is a suite of text-to-image models that define a new state-of-the-art (SOTA) in image detail, prompt adherence, style diversity, and scene complexity for text-to-image synthesis.
It comes in three variants:
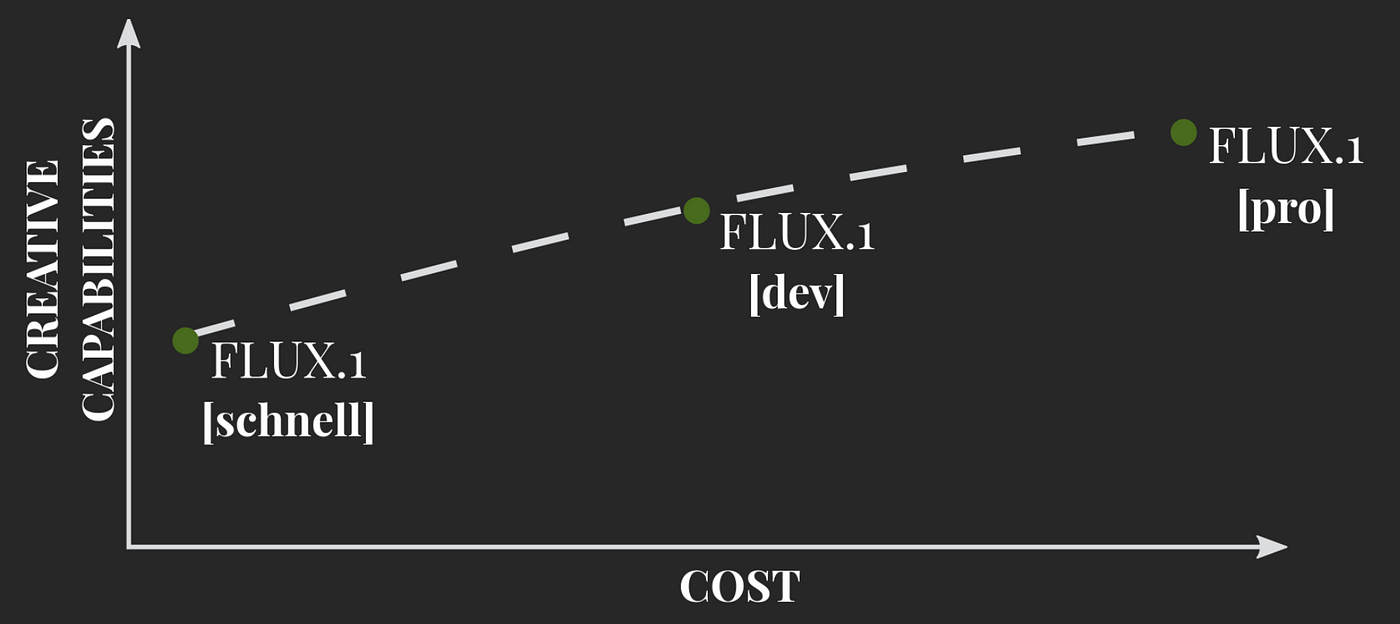
All public Flux.1 models use a mix of multimodal and parallel diffusion transformer blocks and have 12 billion parameters. These models are better than earlier diffusion models because they use flow matching, an easy-to-understand method for training generative models that includes diffusion.
Additionally, the models perform better and use hardware more efficiently by using rotary positional embeddings and parallel attention layers.
According to the researchers, Flux.1 Pro and Flux.1 Dev surpass popular models like Midjourney v6.0, Dall-E3, and Stable Diffusion 3 Ultra in each of the following aspects:
But does it, really? Let’s try this example:
Prompt: old man with glasses portrait, photo, 50mm, f1.4, natural light, Pathéchrome

Flux.1 (left), Midjourney V6.1 (middle), and Midjourney v6.0 (right)
Which one do you think looks best?
All Flux.1 model variants support a diverse range of aspect ratios and resolutions between 0.1 and 2.0 megapixels, as shown in the following example.
Check out some of the mind-blowing example images generated with Flux.1 Pro. Let’s start with images of people with a primary focus on the fine details, like the hair and wrinkles and fingers and limbs.
The quality is very much comparable to Midjourney on the left image. The level of detail in human features like hair, wrinkles, and fingers is remarkable.
Prompt: A robot holding chalk looking at a blackboard that reads the following poem:”ln pixels’ dance, AI’s craft will rise, Transforming visions through machine eyes, From dreams to screens, new worlds unfurled, AI’s brush reshapes our visual world.”

Text rendering is one of the hardest areas in AI image generation. Even the latest version of Midjourney v6.1 still fails on my initial tests. Flux.1 seems to be really good, even with long texts.
Prompt: beautiful anime artwork, a cute anime catgirl that looks depressed holding a piece of paper with a smile drawn on it over her mouth, she is about to cry

This looks incredibly promising. The soft tones and glowing highlights give it a professional, polished look that rivals hand-drawn artwork.
Some users who had access to Flux were quick to discover how eerily realistic the images are. Here are some of the most realistic selfie portraits shared on X.
As someone who’s experimented with various AI image generators, I can confidently say these are some of the most lifelike AI-generated portraits I’ve seen.
For those eager to try Flux.1, there are several free options available:
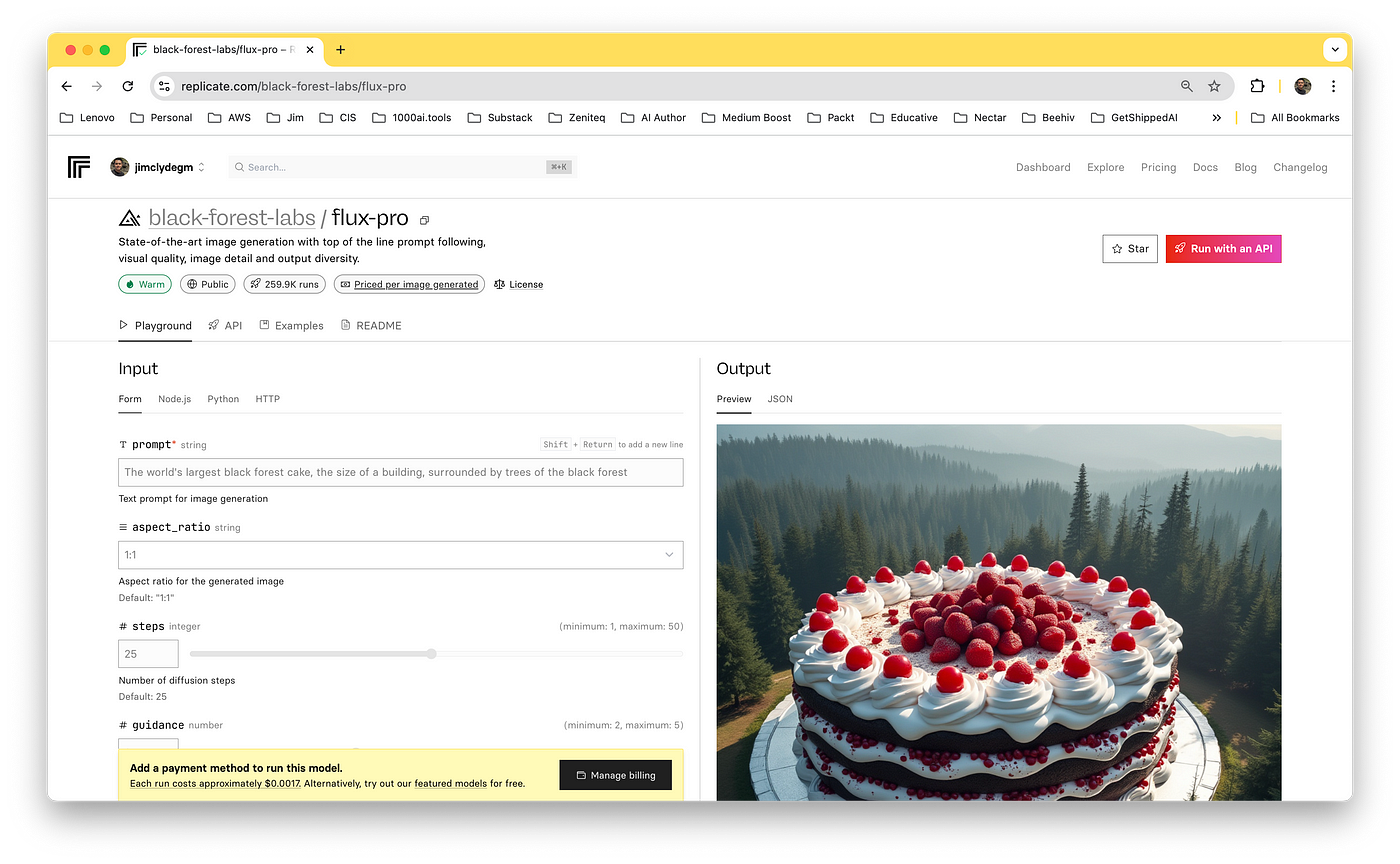
Here’s an example generation with Replicate.
Prompt: The world’s largest black forest cake, the size of a building, surrounded by trees of the black forest
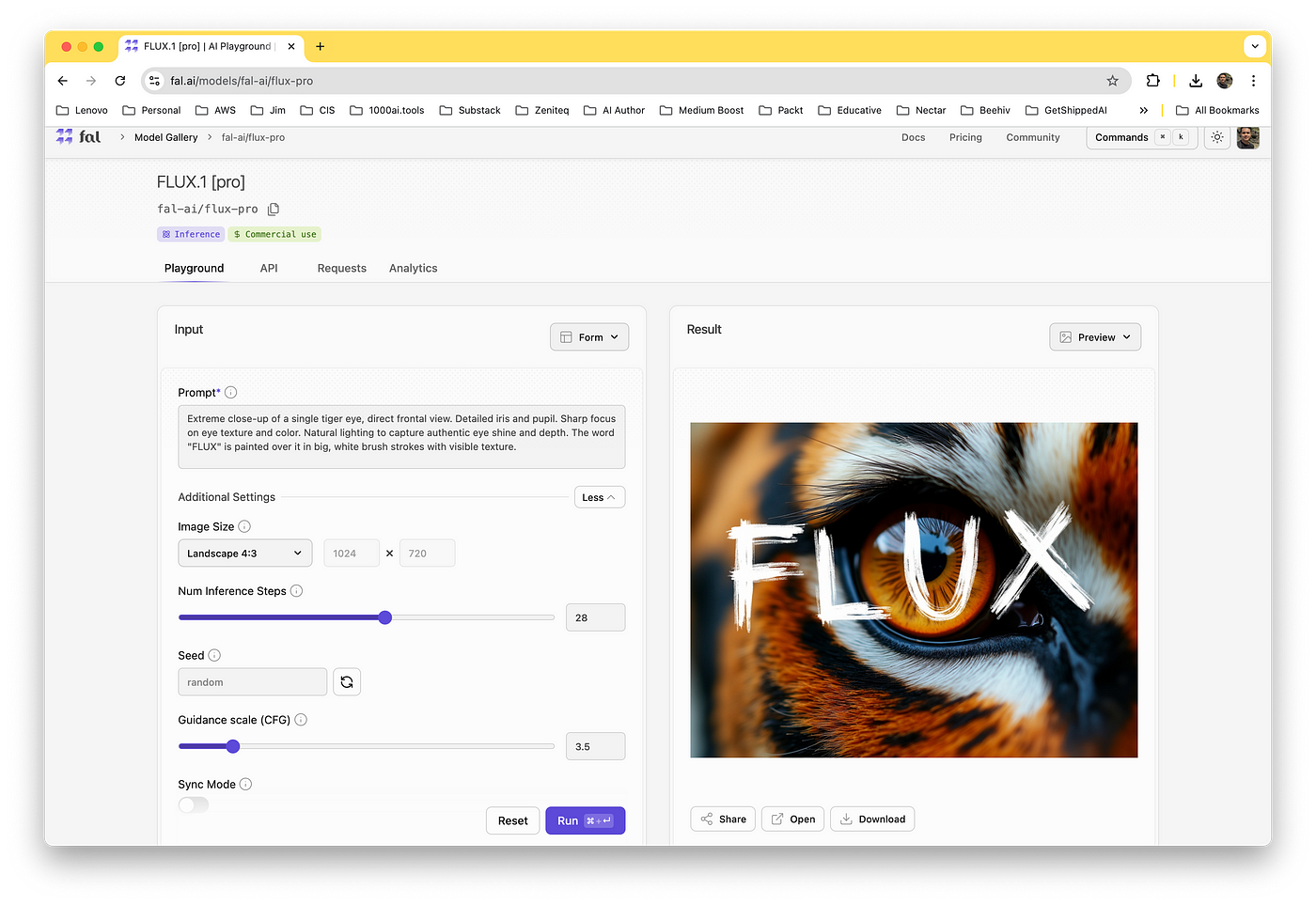
Here’s another demo of Flux in Fal:
Prompt: Extreme close-up of a single tiger eye, direct frontal view. Detailed iris and pupil. Sharp focus on eye texture and color. Natural lighting to capture authentic eye shine and depth. The word “FLUX” is painted over it in big, white brush strokes with visible texture.
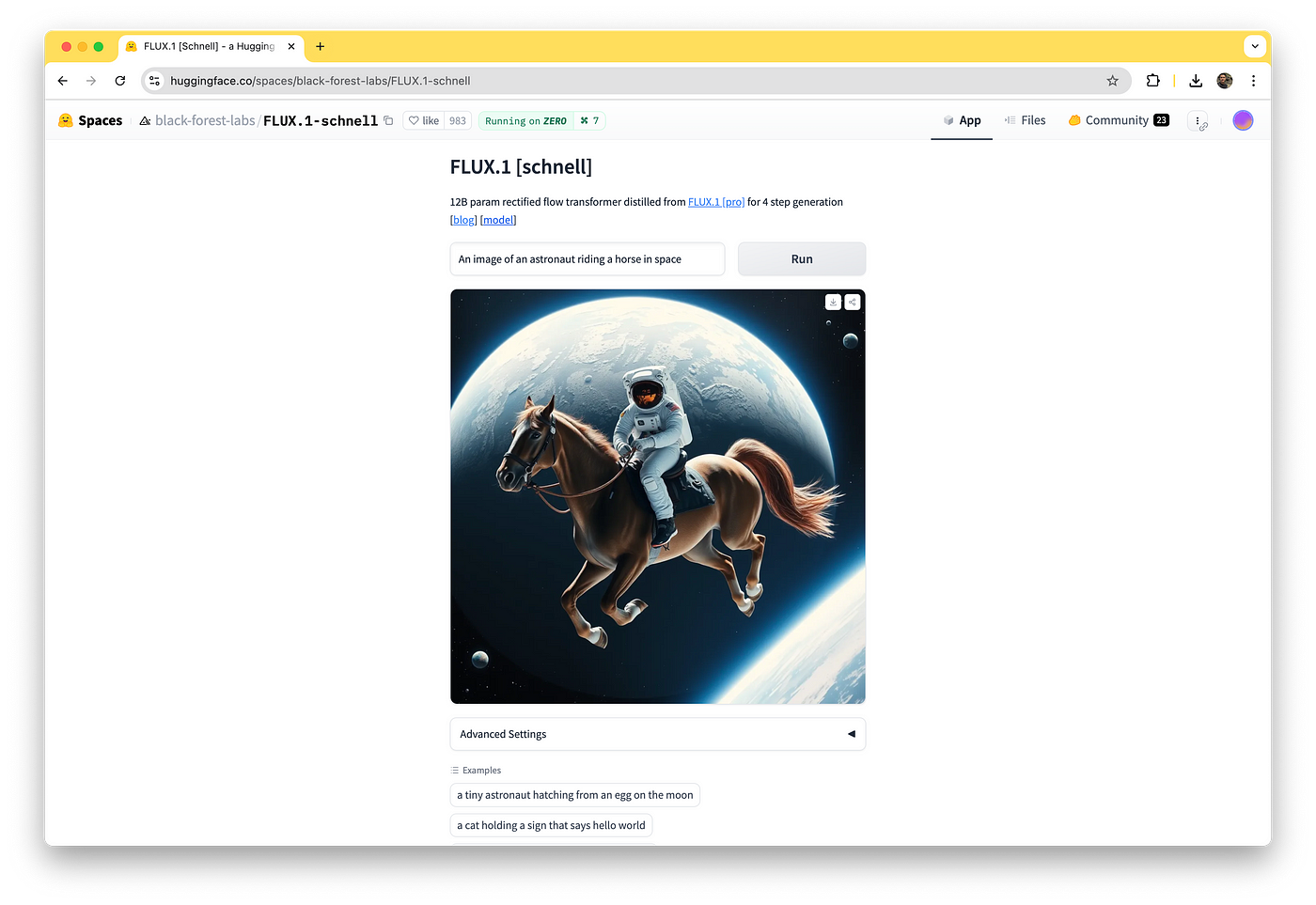
And finally, here’s an example screenshot of Flux in HuggingFace:
Prompt: An image of an astronaut riding a horse in space
Flux.1 Pro can also be accessed via API here. It is currently in preview mode; some limitations apply.
Note that sending requests to /v1/image is limited to 12 active tasks. If you exceed your limit, it will return a status code 429 and you will have to wait until one of your previous tasks has finished.
Check out the full process of how you can use the API here.
Now, some of you might be thinking, can I sell or distribute the images for commercial purposes? Well, the answer is yes or no, depending on the model you use.
In summary, if you are looking to use Flux.1 models for commercial purposes, Flux.1 Pro and Flux.1 Schnell are your best options. Flux.1 Pro provides the highest quality and is available through specific partnerships, while Flux.1 Schnell offers a more accessible solution under an open-source license.
While the open-weight nature of Flux models is exciting, there’s a practical limitation to consider. Running these models locally alongside a large language model (LLM) requires significant computing power—typically an A100 GPU or better. With 12 billion parameters (24 GB on disk) plus a 9 GB text encoder, Flux.1 is beyond the capabilities of most consumer-grade hardware.
The open-weights model, Schnell, is already very good. I have no doubt that the community will work to find novel techniques to tune, train, and extend the step-distilled Apache 2.0 version. I am very excited to see amazing, fine-tuned models come out and generate mind-blowing images.
In the upcoming articles, I will compare Flux with Midjourney, Dall-E 3, and Gemini 2. I also plan to write a guide on how to run Flux Schnell on your local machine.
No FAQ available for this post.

